


Un po' di storia
GraphQL è un linguaggio di interrogazione e manipolazione dati open-source per le API. GraphQL nasce nel 2010 nelle braccia del team di Facebook per poi essere rilasciato pubblicamente nel 2015. Il 7 novembre 2018, il progetto è passato dalle mani di Facebook a quelle della GraphQL Foundation (da cui il nome), ospitata dalla Linux Foundation senza scopo di lucro.
Lee Byron, il co-creatore di GraphQL, nel 2015 aveva stimato un’ottimistica timeline dell’ascesa della sua creazione, stimando che sarebbe stata adottata da:
startup e piccole imprese nel giro di un anno;
medie imprese nel giro di due anni;
grandi compagnie nel giro di 4 anni;
qualsiasi piattaforma web nel giro di 5 anni.
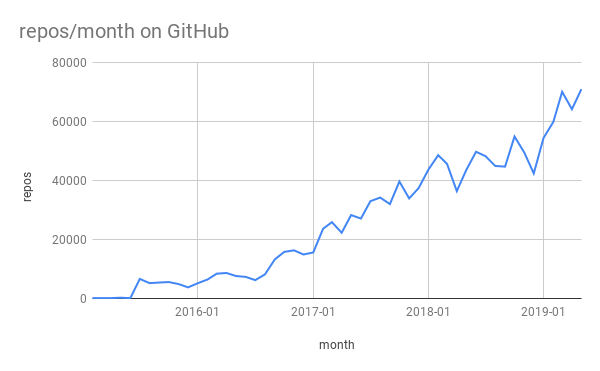
La previsione di Lee non si è rivelata poi così errata, almeno fino al penultimo punto. Oggi (Marzo 2020) un gran numero di colossi del web fa uso di GraphQL (tra questi Coursera, Twitter, Yelp, StackShare, Microsoft) e possiamo quindi dire di trovarci nella fase delle grandi compagnie, con, per adesso, solo un anno di ritardo rispetto alla timeline di Lee.
Lasciamo fare al client!
GraphQL rivoluziona l’approccio REST (o architetture simili) introducendo un concetto piuttosto insolito... La definizione della struttura dati avviene lato client! Il server si attiene a questa struttura e restituisce i soli dati effettivamente necessari. Come si vedrà con un esempio più avanti, questo approccio porta notevoli vantaggi in termini di overfetching e underfetching. L’unica ripercussione negativa si ha in termini di efficacia per quanto riguarda la memorizzazione dei risultati nella cache.
Perché GraphQL?
Come per ogni nuova tecnologia che si propone di rivoluzionare uno standard, ci sono due domande più che lecite:
perché Facebook ha sentito la necessità di rivoluzionare un sistema consolidato di utilizzo delle API?
perché, io sviluppatore, dovrei passare a GraphQL?
Dunque, vediamo di rispondere a queste domande.
Overfetching e underfetching
Per rispondere alla prima domanda analizziamo il funzionamento di entrambi gli approcci con un esempio verosimile. Supponete di avere un blog e in una certa pagina avete la necessità di mostrare i titoli di tutti i post di uno specifico utente. Inoltre, volete mostrare il nome degli ultimi 3 follower di quell’utente.
In un ambiente REST i suddetti dati si ottengono accedendo a differenti endpoint; nello specifico, avrete bisogno delle seguenti tre chiamate:
/user/{id} per ottenere i dati dell’utente
/user/{id}/posts per recuperare i post di quell’utente
/user/{id}/followers per recuperare i suoi follower
Ognuna di queste tre chiamate è soggetta a ciò che viene definito overfetching ossia la restituzione di molti più dati di quelli effettivamente necessari.
Infatti, è molto probabile che dell’utente principale vi serva soltanto il nome e quasi sicuramente non avrete bisogno dell’indirizzo o altri dati secondari che la API comunque vi restituisce. Stessa cosa vale per i post, dei quali in tutta probabilità vi servirà solo il titolo e non l’intero corpo o i commenti. E così via.
Con l’utilizzo di GraphQL il tutto si semplifica in un’unica chiamata al server che include tutti e solo i dati necessari.
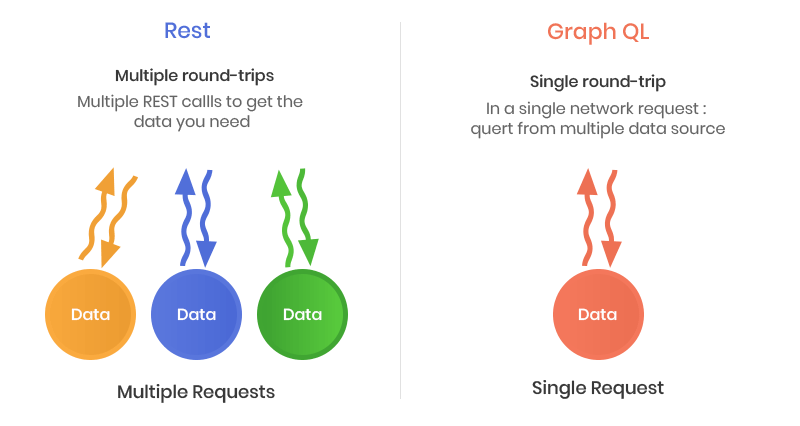
La risposta è un oggetto JSON rispecchiante la struttura richiesta dal client. Dunque, a fronte di una richiesta come questa:
query {
User(id: "eb3d0439fb30") {
name
posts {
title
}
followers(last: 3) {
name
}
}
}Il server vi fornirà una risposta simile a questa:
{
"data": {
"User": {
"name": "Francesco",
"posts": [
{"title": "Nuove tecniche di pesca"},
{"title": "La carpa e le sue abitudini"}
],
"followers": [
{"name": "Luca"},
{"name": "Michele"},
{"name": "Giovanni"}
]
}
}
}Da notare appunto, che la struttura della risposta rispecchia esattamente quella della richiesta.
Detto questo potrei anche pensare: visto che la gestione delle API è in mano mia, chi mi impedisce di creare un endpoint specifico che restituisca esattamente i dati di cui ho bisogno? Assolutamente nessuno! Dunque a questo punto REST e GraphQL si equivalgono? No.
Poniamo il caso che il cliente tra un anno ci chieda una revisione alla UI e voglia mostrare dati diversi da quelli concordati al tempo dell’implementazione del mio endpoint. Incorriamo qui in due rischi:
overfetching, come abbiamo visto precedentemente, è l’ottenimento di più dati di quelli che effettivamente servono;
underfetching, è, al contrario, l’ottenimento di meno dati di quelli di cui ho bisogno (caso ben peggiore).
A questo punto, per ogni pagina per cui si è creato un endpoint su misura, sarà necessario andare a controllare, e in tutta probabilità a modificare, il codice dell’API.
In ambiente GraphQL invece (fatta eccezione per quei casi in l’applicazione subisca una ristrutturazione completa, che preveda la nascita di nuove entità e nuove relazioni) non avrò bisogno di intervenire sul server, ma basterà ricostruire lato client la struttura dei dati richiesti e il server sarà pronto a rispondere con la nuova struttura.
Quando sì, quando no
Alla seconda domanda, non c’è una risposta precisa; non c’è nessun obbligo e neanche alcuna raccomandazione e sia REST che GraphQL sono chiaramente due approcci validissimi. Dunque la decisione di adottare l’una o l’altra architettura non dipende dalla qualità, bensì dalle necessità specifiche del progetto che si sta iniziando.
Quando no
E' preferibile rimanere fedeli all’approccio REST in tutti quei casi in cui:
le entità e le relazioni in gioco sono poche
non si prevedono frequenti e/o massicce ristrutturazioni della UI e di conseguenza della fruizione dei dati
Se quindi state realizzando un’app piuttosto semplice con pochi endpoint e poche richieste, probabilmente l’approccio REST rimane il migliore poiché non avrete bisogno di molte righe di codice per costruire le vostre API. Mettere in piedi e configurare un server GraphQL per poco più di un paio di entità sarebbe probabilmente time-consuming e controproducente.
Quando sì
In caso invece di un’applicazione più complessa che preveda frequenti cambiamenti nell’interfaccia o di progetti che prevedono diversi step di upgrade, probabilmente un approccio GraphQL risulterà più semplice e produttivo. Una volta configurato il server e stabilite le interazioni tra gli oggetti, non ci sarà più bisogno di mettere mano al server.
Let's code!
Abbiamo detto che mettere in piedi un ambiente GraphQL è un’operazione piuttosto semplice e veloce. Vediamo quindi quali sono gli step necessari prima di poter iniziare a scrivere codice.
Per prima cosa avremo bisogno di un server. GraphQL mette a disposizione server per molti linguaggi, tra cui: Haskell, JavaScript, Perl, Python, Ruby, Java, C#, Scala, Go, Elixir, Erlang, PHP, R, e Clojure. Per la gestione del workflow dei progetti, il nostro team fa uso di Docker (leggi il nostro articolo su Docker) e pertanto la scelta è ricaduta su apollo-server, che si appoggia a sua volta su un server NodeJS.
Avremo poi bisogno si due dipendenze NPM:
mongoose un tool di object modeling per MongoDB studiato e disegnato per lavorare in ambienti asincroni, supporta promises e callback;
graphql-tools un tool per la generazione e il mock di schemi GraphQL.
Una volta messo in piedi il server (nel nostro caso Docker, con NodeJS e apollo-server) e le suddette dipendenze, il nostro ambiente è pronto e, anche totalmente vergine e senza connessioni a database, avviabile.
Per farlo sarà sufficiente creare il nostro file di partenza
// src/index.ts
import { ApolloServer } from 'apollo-server';
import { makeExecutableSchema } from 'graphql-tools';
import { merge } from 'lodash';
import mongoose from 'mongoose';
import rootTypeDefs from './root';
import { userResolvers, userTypeDefs } from './common/user/user.schema';
import { workspaceResolvers, workspaceTypeDefs } from './common/workspace/workspace.schema';
import { petResolvers, petTypeDefs } from './common/pet/pet.schema';
import User from './common/user/user.model';
import config from './config';
/*
Connect to the mongodb database using
the mongoose library.
*/
mongoose.connect(
config.mongodb.uri,
{ useNewUrlParser: true }
);
/*
Declare the schema which will hold our
GraphQL types and resolvers.
*/
const schema = makeExecutableSchema({
typeDefs: [rootTypeDefs, userTypeDefs, workspaceTypeDefs, petTypeDefs],
resolvers: merge(userResolvers, workspaceResolvers, petResolvers),
});
/*
Create the server which we will send our
GraphQL queries to.
*/
const server = new ApolloServer({
schema,
formatError(error) {
console.log(error);
return error;
}
});
/*
Turn the server on by listening to a port
Defaults to: http://localhost:4000
*/
server.listen().then(({ url }) => {
console.log(`🚀 Server ready at ${url}`);
});In seguito questo file dovrà essere integrato con un sistema di verifica di autenticazione, ad esempio JSON Web Token (meglio conosciuto come JWT).
Andranno quindi creati i file contenenti le definizioni dei tipi, delle query, delle mutations, dei resolvers e di quant’altro sia necessario al corretto funzionamento del server in ambiente reale.
Tali file, che nell’esempio sopra abbiamo già incluso, sono i seguenti:
/src/root.ts
/src/config.ts
/src/common/pet/pet.model.ts
/src/common/pet/pet.schema.ts
/src/common/user/user.model.ts
/src/common/user/user.schema.ts
/src/common/workspace/workspace.model.ts
/src/common/workspace/workspace.schema.ts
A questo punto non ci resta che definire i nostri modelli. Un modello è una rappresentazione di una tabella del database (o di una collection, se parliamo di MongoDB). Come esempio riporto il file
/src/common/users/user.model.ts
che descrive un utente tramite le sue proprietà utilizzando mongoose.
import bcrypt from 'bcryptjs';
import mongoose from 'mongoose';
/**
* Here is the our user schema which will be used to
* validate the data sent to our database.
*/
const userSchema = new mongoose.Schema({
workspaceId: {
type: mongoose.Schema.Types.ObjectId,
ref: 'Workspace', // this must match the name we assigned to the workspace model
},
email: {
type: String,
required: true,
unique: true
},
password: {
type: String,
required: true
},
firstName: {
type: String,
required: true,
},
lastName: {
type: String
}
});
/**
* This property will ensure our virtuals (including "id")
* are set on the user when we use it.
*/
userSchema.set('toObject', { getters: true, virtuals: true });
/**
* Never save the password directly onto the model,
* always encrypt first.
*/
userSchema.pre('save', function preSave(this: any, next: () => {}) {
if (!this.isModified('password')) {
next();
} else {
bcrypt
.genSalt(5)
.then(salt => bcrypt.hash(this.password, salt))
.then(hash => {
this.password = hash;
next();
})
.catch(next);
}
});
/**
* Adds a method on the user object which we can use
* to compare a user's password with.
*/
userSchema.method('comparePassword', function comparePassword(
this: any,
candidate: string
) {
if (!this.password) {
throw new Error('User has not been configured with a password.');
}
if (!candidate) {
return false;
}
return bcrypt.compare(candidate, this.password);
});
/**
* Finally, we compile the schema into a model which we then
* export to be used by our GraphQL resolvers.
*/
export default mongoose.model('User', userSchema);Dunque adesso abbiamo il nostro ambiente GraphQL e un modello che possiamo usare per salvare e richiedere dati al nostro database. Tutto ciò che dobbiamo fare è metterli in comunicazione!
Per farlo abbiamo bisogno di:
un set di tipi GraphQL che specifichi al client di quali dati il server disponga;
un set di funzioni resolver che indichi al server come fare le cose che vengono descritte dai nostri tipi
Entrambe le cose devono essere incluse all'interno del file ‘schema’ che utilizzerà il file ‘modello’ sopra descritto. Nel nostro specifico caso si tratta del file /src/common/user/user.schema.ts, strutturato come segue:
import User from './user.model';
import config from '../../config';
import Workspace from '../workspace/workspace.model';
/**
* Export a string which contains our GraphQL type definitions.
*/
export const userTypeDefs = `
type User {
id: ID!
workspaceId: String
workspace: Workspace
email: String!
password: String!
firstName: String!
# Last name is not a required field so it does not need a "!" at the end.
lastName: String
}
input UserFilterInput {
limit: Int
}
# Extending the root Query type.
extend type Query {
users(filter: UserFilterInput): [User]
user(id: String!): User
}
# We do not need to check if any of the input parameters exist with a "!" character.
# This is because mongoose will do this for us, and it also means we can use the same
# input on both the "addUser" and "editUser" methods.
input UserInput {
email: String
password: String
firstName: String
lastName: String
workspaceId: String
}
# Extending the root Mutation type.
extend type Mutation {
addUser(input: UserInput!): User
editUser(id: String!, input: UserInput!): User
deleteUser(id: String!): User
loginUser(email: String!, password: String!): String!
}
`;
/**
* Exporting our resolver functions. Note that:
* 1. They can use async/await or return a Promise which
* Apollo will resolve for us.
* 2. The resolver property names match exactly with the
* schema types.
*/
export const userResolvers = {
Query: {
async users(_, { filter = {} }) {
const users: any[] = await User.find({}, null, filter);
// notice that I have ": any[]" after the "users" variable?
// That is because I am using TypeScript but you can remove
// this and it will work normally with pure JavaScript
return users.map(user => user.toObject());
},
async user(_, { id }) {
const user: any = await User.findById(id);
return user.toObject();
},
},
Mutation: {
async addUser(_, { input }) {
const user: any = await User.create(input);
return user.toObject();
},
async editUser(_, { id, input }) {
const user: any = await User.findByIdAndUpdate(id, input);
return user.toObject();
},
async deleteUser(_, { id }) {
const user: any = await User.findByIdAndRemove(id);
return user ? user.toObject() : null;
},
async loginUser(_, { email, password }) {
const user: any = await User.findOne({ email });
const match: boolean = await user.comparePassword(password);
if (match) {
return true;
}
throw new Error('Not Authorised.');
},
},
User: {
async workspace(user: { workspaceId: string }) {
if (user.workspaceId) {
const workspace: any = await Workspace.findById(user.workspaceId);
return workspace.toObject();
}
return null;
}
}
};Conclusioni
La versatilità e la semplicità di GraphQL sono indubbie, ma potrà davvero questo nuovo modo di fare API soppiantare il caro vecchio approccio REST?
Come abbiamo visto, Lee Byron aveva fatto una stima piuttosto veritiera sull'ascesa di questa tecnologia, fatta eccezione per l'ultimo step che prevedeva (già per il 2020) l'adozione di GraphQL da parte di tutte le piattaforme web.
Oggi siamo ancora ben lontani da questo traguardo e l'approccio REST sembra vendere cara pelle. Abbiamo visto che la scelta dell'uno o dell'altro sistema dipende molto dal caso d'uso del nostro progetto ed è difficile dare a priori una risposta univoca.
Inoltre, adottare una nuova tecnologia rappresenta spesso uno sforzo non banale in termini di tempo e costi e per soppiantare un sistema REST con GraphQL un'azienda si vedrebbe costretta a ristrutturare sistemi già funzionanti nonché, in alcuni casi, chiedere ai propri clienti di adattarsi alla nuova architettura. Dunque è comprensibile che un tale sistema "rivoluzionario" fatichi ad attecchire globalmente. Vista la giovane età di GraphQL però, è presto per stabilire se con il tempo potrà o meno diventare il nuovo standard. Chissà, forse con qualche ulteriore improvement o con l'aggiunta di qualche feature allettante il team di Facebook riuscirà a convincere il web.